System Design of Job scheduler in Golang
| Last Edited | |
|---|---|
| Tags |
Background
Container tech in recent years has been used a lot in web development. I am very interested in engineering some useful applications that works in docker and Kubernetes environment. In previous posts, I wrote down my study of K8S system. In this post, I am going to continue my journey and build tools with GoLang. This post will be more formal, similar to a system design document.
Functional requirements
Design a microservices system works as periodically crawling job information. Then send out email notification based on user preference. It should be in golang, docker, and k8s (potentially) for studying purpose.
- Types of jobs and numbers of companies to crawl is limited (<10 companies * 3 types), therefore concurrent processing is ok. In K8S situation (distributed service), this will be K8S nodes and Pods. If this scales to a hundred or thousand crawling task at the same time, then a message queue is needed. (Out of Scope)
- Task status update: set a web server having an endpoint (“tasks/<uuid>”) to update task. Here’s the workload estimation of the web server. Since concurrent crawlers are limited to 30 and each crawling in 2 hours window have around 20 new jobs, 600 requests will be there. Suppose 500 ms in average each worker can complete crawling for a job posting, then there will be 2 * 30 = 60 requests per second, this is ok for a simple DB update.
- Suppose the system has thousands or millions of subscribers, then a queue is needed before sending user email notification.
Design choice
- Golang for job scheduler manager, because it is designed for high concurrent applications, and easy to communicate with kubernetes services.
- Python for crawler. Python has build in easy-to-use crawling and html parser modules like selumni and beautiful soup.
- Docker for containerization. Each unit is containerized and serves as microservice, which can be managed by kubernetes or docker-compose.
- RabbitMQ for emailing queuing. I am only handling cases where there are lots of subscribed users and limited numbers of crawling objects. In this case, message queue is needed to send user notification.
- Postgres for storing task, job, and user info. possibly add indexing on task uuid to speed up writes.
- MongoDB for storing crawled job information. URL would be the key to check a particular job is visited or not.
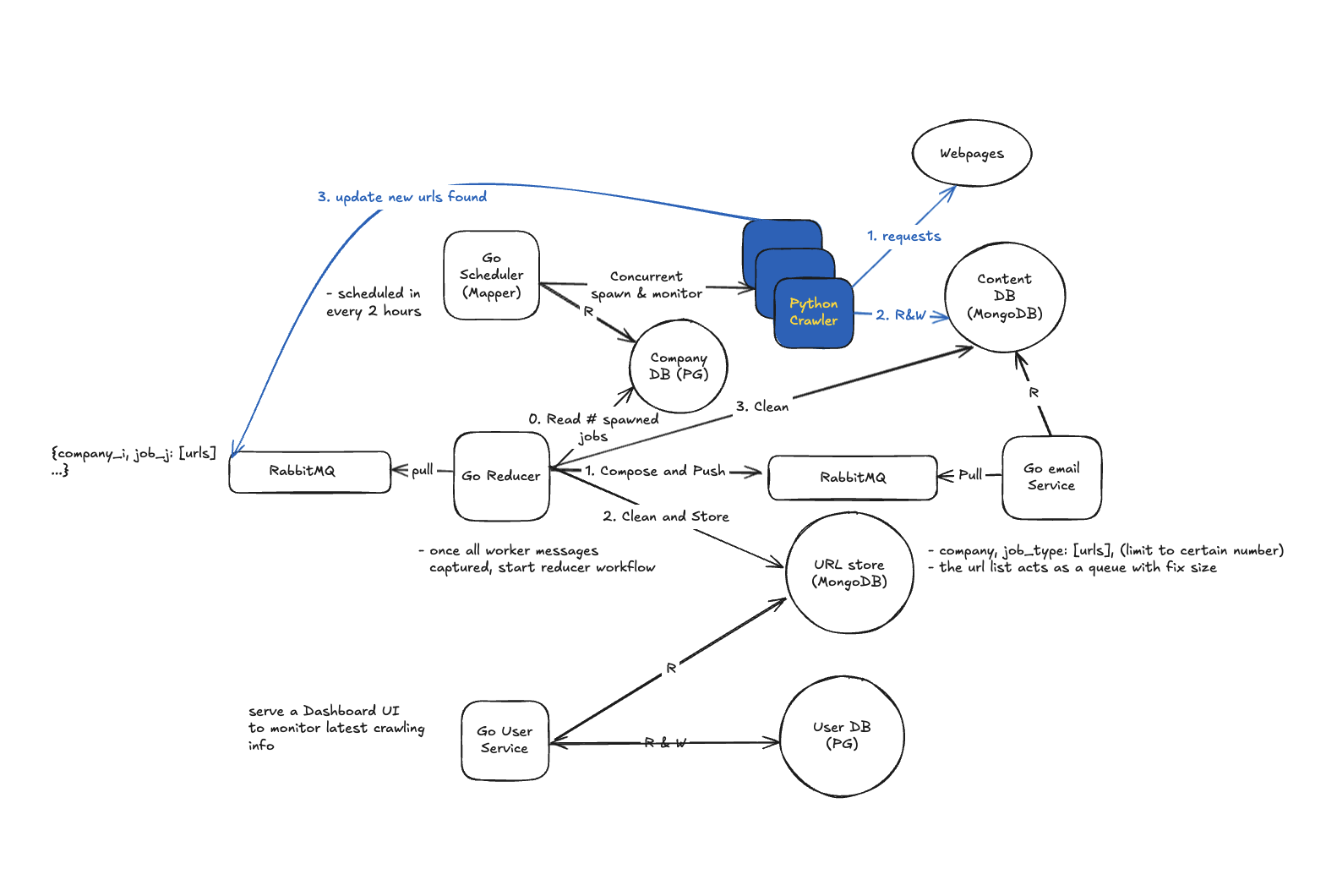
Overall Design
Detailed Design
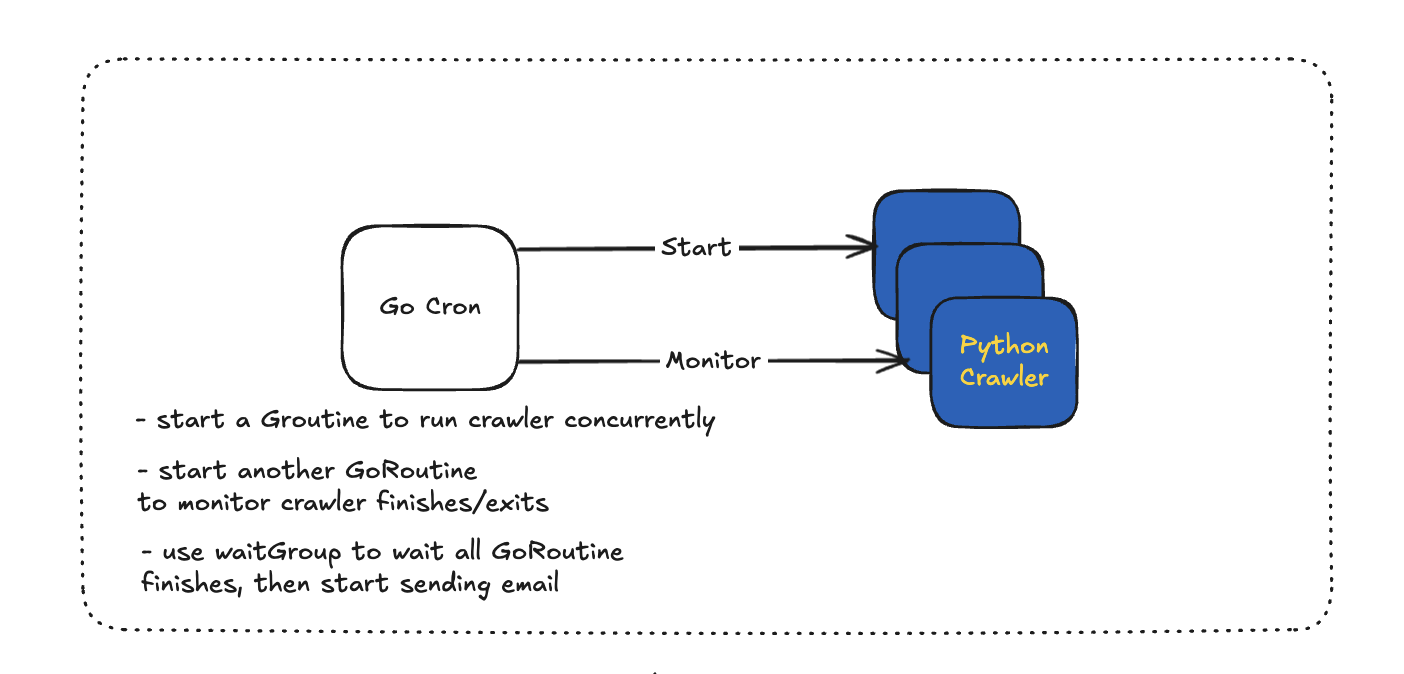
— Go Cron (Scheduler)
- as shown in graph, there will be two threads to start and monitor python crawler.
- in docker env, go cron expose its docker.socket (unix domain socket) and communicate through writing and reading to the file
- in k8s env, go cron will communicate k8s api server to spawn new process. (depending time, this may be not implemented)
- as for concurrency control, the design is to pass a env variable about numbers of concurrent threads and then use semaphore to control numbers of concurrent threads
— Task Service and User Service
- They are two backend microservices. Task service handles all task related api and does not expose to end users. User service handles all user related apis and only have access to user database.
- This way services are isolated, and better for scalability and availability.
— Deduplicate urls
- Since for each company I search for different keywords, same job links can be found by different workers (e.g. amazon-data-scientist, amazon-data-analysis). I perform deduplication in the following ways.
- In worker phase, adding a
job_typesfield for mongoDB, when same job link found for each search, attach search keyword to each job detail entry in database, and still tell task service this is new found url. This way database will only have one entry, but each task will have correct amount of findings.
- In composing email phase, for each user, simply get a unique set of all job ids for all job types user interested in.
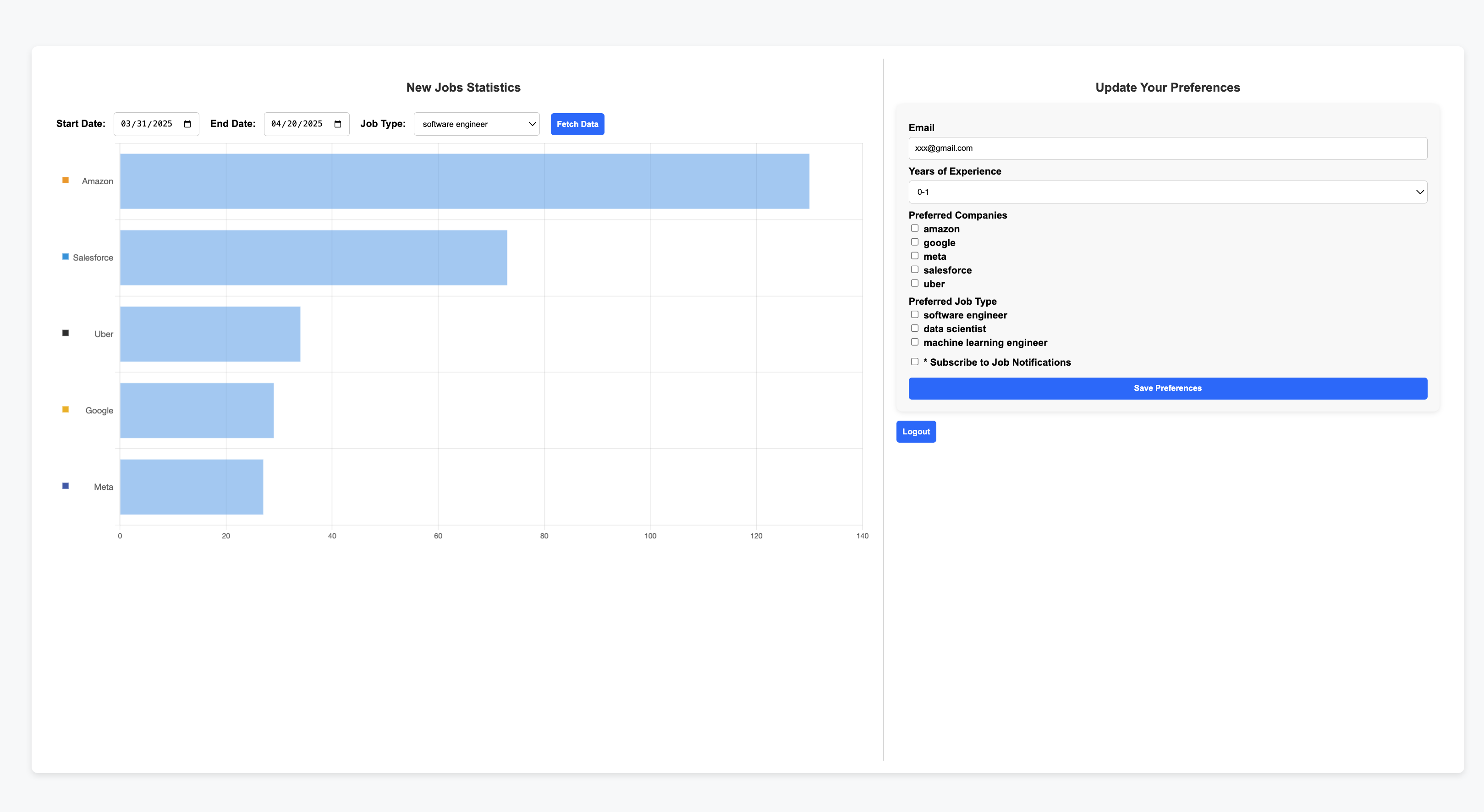
UI and Email

Final thoughts
- Task service handles email sending after all tasks are done. In order to find all users interested in the new finding, it loops through the user table. It’s expensive. Although I made it as async api call, there’s better option. One idea is to add replica of web servers each handling users subscripted to company and job type pair. Even better, I can set up queues and a listener, instead of an async api, to further decouple and expand the system.
- For example,
- Web Server 1/ Consumer 1:
- amazon: data scientist: [user1, user2, user3,…]
- amazon: machine learning engineer: [user1, user2, user3,…]
- Web Server 2/ Consumer 2:
- google: data scientist: [user3, user4, user5,…]
- google: machine learning engineer: [user5, user6, user7,…]
- For example,
- For simplicity, I use backend served Vue.js and html for user frontend and skip separating it to another microservice. In a more complex design, it often involves load balancer and more complexed authentication service, such as AWS API Gateway.
- 🙂 I spent months to write the project in my spare time, and each day or week I have new thoughts about the system. Sometimes ideas is small and sometimes idea is too big to complete. Hopefully, the initial ideas of the project (even a bit more) are completed!
I am very thankful to ChatGPT and Amazon Q, both help me to establish ideas and work efficiently.
* Notes for EC2 Setup
- git
sudo yum update -y sudo yum install git -y
- docker
- docker-compose
sudo curl -L https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose docker-compose version